RAG(検索拡張生成)の仕組みとデータフロー解説
RAGとは何か
RAG(Retrieval-Augmented Generation、検索拡張生成)とは、大規模言語モデル(LLM)の応答生成プロセスに「検索(情報検索)機能」を組み合わせることで、外部の知識を参照しながら回答を生成する手法です (What is Retrieval-Augmented Generation (RAG)? A Practical Guide)。もともと2020年にFacebook AI(現Meta)が発表した研究論文で提唱されたアーキテクチャで、LLMに社内の知識ベースやドキュメントなど信頼できるデータを接続し、より最新で正確な回答を得ることを目的としています (What is Retrieval-Augmented Generation (RAG)? A Practical Guide)。通常のLLM単体では学習データに含まれる知識に頼って回答しますが、RAGではユーザーからの質問に応じて関連情報を検索し、その情報をコンテキストとしてLLMに与えることで、知識に裏付けされた回答を得ることができます (What is Retrieval-Augmented Generation (RAG)? A Practical Guide)。
こうした仕組みにより、LLMだけでは困難だった最新情報への対応や正確性の向上が期待できます。例えば、大量の社内文書を参照して回答する社内チャットボットや、最新のニュースやデータに基づく質問応答システムなどにRAGが活用されています。企業にとっては、自社の蓄積したデータ(ナレッジ)を生成AIに組み込める点で注目されており、「LLM+社内検索エンジン」のようなイメージで捉えると分かりやすいでしょう。
RAGの基本構成とデータフロー
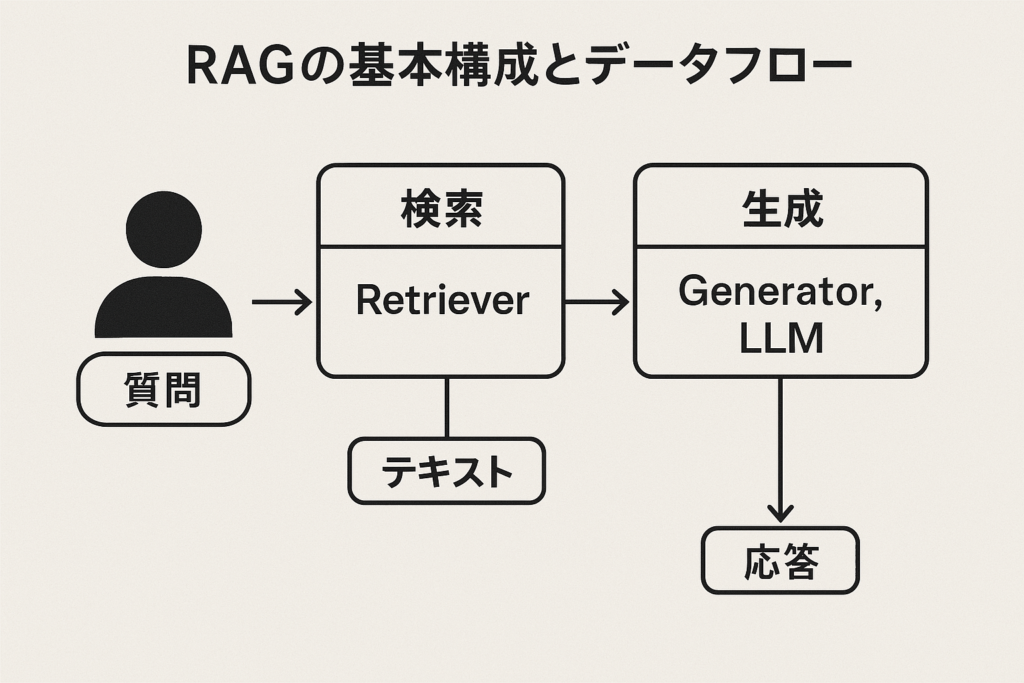
RAGシステムは大きく検索パート(Retriever)と生成パート(Generator, LLM)の2つのコンポーネントから構成され、ユーザーの質問処理は以下のデータフローで進みます (Seven RAG Pitfalls and How to Solve Them | Label Studio)。
(image)
図: RAG(検索拡張生成)の典型的なデータフロー。 ユーザーからの質問(プロンプト)がまず検索モジュール(Retrieval Model)に渡され、社内外の知識ソース(構造化データベースやドキュメントなど)から関連情報を検索します。検索された情報はコンテキスト付きプロンプトにまとめられ、生成モデル(LLM)に入力されます。LLMは提供されたコンテキストと自身の言語モデル知識を組み合わせて回答を生成し、最終的にユーザーへ回答が返されます。このように、ユーザーの問い合わせから回答が生成されるまでの間に、必要な知識を動的に検索して活用する点がRAGの特徴です。
データフローの主なステップ
RAGの処理フローをステップごとに見てみましょう。
- インデキシング(事前準備): まずRAGシステムで扱うドキュメントやデータをあらかじめ読み込み、検索しやすいようにインデックスを作成します。具体的には、PDFやテキスト、HTMLなどの社内文書から本文テキストを抽出し、小さなチャンク(断片)に分割します。その上でベクトル埋め込みモデルを用いて各チャンクをベクトル(数値表現)に変換し、ベクトルデータベース(もしくは検索インデックス)に格納します (Why your RAG is not working?. Pitfalls of simple retrieval, solutions… | by Saurabh Singh | Medium)。この準備段階により、高速な類似検索が可能な知識ベースが構築されます。
- 検索(Retrieval): ユーザーから質問が入力されると、まずそのクエリ(質問文)に対してベクトルへの変換が行われます。変換されたクエリベクトルをもとに、先ほど構築したベクトルデータベースに対して類似度検索を実行します。クエリと意味的に最も近いベクトルを持つ上位K件の文書チャンクが検索で取得されます (Why your RAG is not working?. Pitfalls of simple retrieval, solutions… | by Saurabh Singh | Medium)。必要に応じてスコアの高い順にソートしたり、スコア閾値で足切りすることで、関連性の高い情報のみを選別します。検索パートの役割は、ユーザーの質問に直接関連する知識の断片を素早く取り出すことにあります。
- 生成(Generation): 次に、取得された関連文書の断片群をコンテキスト情報としてユーザーの質問と結合し、一つのプロンプト(文章)にまとめます。この「質問+関連情報」のプロンプトをLLMに与えることで、LLMは質問に対して関連情報を踏まえた回答を生成します (Why your RAG is not working?. Pitfalls of simple retrieval, solutions… | by Saurabh Singh | Medium)。生成された回答はユーザーに返答されます。ここで生成パートの役割は、検索で得た知識(コンテキスト)を活用しつつ、人間が読みやすい自然言語の回答を作り出すことです。
以上がRAGの基本的なデータフローです。ポイントとして、検索パートが適切な知識を引き当て、生成パートがそれを元に回答を作るという協調動作になっています。したがって、検索と生成の両方がうまく機能することで初めてユーザーに有用な回答が得られます (Seven RAG Pitfalls and How to Solve Them | Label Studio)。
検索部分(Retriever)の役割と処理ステップ
RAGにおける検索部分(Retriever)は、ユーザーの質問に関連する情報を素早く見つけ出す重要な役割を担います。具体的な処理ステップとしては前述の通り、クエリをベクトル化してベクトル類似検索を行い、関連度の高い文書スニペットを取得します (Why your RAG is not working?. Pitfalls of simple retrieval, solutions… | by Saurabh Singh | Medium)。この際、検索精度がシステム全体の精度を左右します。Retrieverが正しく関連情報を引き出せなければ、後段のLLMは正確な回答を生成できません。実際、RAGシステムでは「検索段階で適切な文書を取得できない」「ノイズの多い無関係な文書を拾ってしまう」といった問題が生じると、どれほど高性能なLLMでも正しい答えを返すことは難しくなります (Seven RAG Pitfalls and How to Solve Them | Label Studio)。
検索部分では以下の点が重要です:
- ベクトル検索による意味検索: キーワードの完全一致ではなく意味的な関連度で文書を探せるため、言い回しが異なっても関連内容を見つけられます。ただし、後述するように汎用的な埋め込みモデルではドメイン固有のニュアンスが捉えきれず、表面的に似た無関係文書(※いわゆる*「ニアミス」*)を拾う可能性もあります (Why your RAG is not working?. Pitfalls of simple retrieval, solutions… | by Saurabh Singh | Medium)。
- スコアリングとフィルタリング: 検索結果から上位K件を選ぶ際、関連度スコアに基づくランク付け(ランカー)や再ランク(リランカー)の精度も重要です。関連情報が上位に来ないと、必要な知識がLLMに渡らず精度低下の原因となります (Seven RAG Pitfalls and How to Solve Them | Label Studio)。逆にKを増やしすぎるとノイズが増えるため、再現率(網羅性)と適合率(正確性)のバランスを取ることも求められます。
このように、Retrieverは「質問に答えるために必要な情報を漏れなく、かつノイズを最小限に集める」役割を果たします。RAGでは検索部分が事実上フィルタとなってLLMに渡す知識を制御するため、システム精度の要となる部分です。
生成部分(Generator)の役割と処理ステップ
生成部分(Generator)は通常、大規模言語モデル(GPT系モデルなど)が担い、検索で集められたコンテキスト情報とユーザー質問を入力として自然言語の回答を生成します (Why your RAG is not working?. Pitfalls of simple retrieval, solutions… | by Saurabh Singh | Medium)。生成パートに期待されるのは、与えられたコンテキストを正しく参照しながら一貫性のある回答を作ることです。その処理ステップは内部的にはLLMのテキスト生成そのものであり、プロンプト(質問+コンテキスト)を元に確率的に次の単語を生成して文章を組み立てていく流れになります。
生成部分のキーとなるポイント:
- コンテキストの活用: 良いRetrieverからRelevantな情報が渡されたとしても、LLMがそれを無視したり誤って解釈したりすれば正確な回答には結びつきません。プロンプトの設計やシステムメッセージで「与えられた情報に基づいて答える」旨を指示するなど、LLMがコンテキストを最大限活かす工夫が重要です。適切に設計された場合、LLMはコンテキスト内の答えを抜き出したり要約してユーザーに提供できますが、設計が不十分だとコンテキストにないことを勝手に補完(いわゆる幻覚の発生)してしまう恐れがあります (RAG vs. Fine-tuning | IBM)。
- 回答の整形: LLMは与えられた情報を元に文章を作りますが、そのままではユーザーにとって分かりづらい形式になることもあります。例えば箇条書きの質問に対して段落で答えてしまったり、JSON形式で答えてほしい場面で自由文章を返すケースです (Seven RAG Pitfalls and How to Solve Them | Label Studio)。そのため、回答形式や詳細さ加減についてもプロンプトで指示したり、モデルを調整する必要があります。
生成部分は最終的なユーザー体験に直結するため、正確性だけでなく可読性や有用性も考慮すべきポイントです。せっかく検索部分が有用な情報を引き当てても、生成部分が冗長すぎる回答や部分的な回答しか返さなければユーザー満足度は下がります (Seven RAG Pitfalls and How to Solve Them | Label Studio) (Seven RAG Pitfalls and How to Solve Them | Label Studio)。したがって、RAG導入時には生成パートについても回答品質の評価基準を設け、必要に応じてプロンプトの改善やモデル出力の後処理(フォーマッティングの統一など)を行うことが望ましいです。
RAG導入時によくある落とし穴(精度が出ない原因)
RAGを実際に業務導入する際、精度が思うように出ない・期待した回答が得られないといったつまずきがしばしば報告されます。その代表的な原因(落とし穴)を挙げ、その背景を解説します。
- 知識ベースの不足・カバレッジ不足: 最も根本的な問題は、検索対象となるデータ自体に答えが存在しないケースです。システムの知識ベース(インデックス化された社内文書など)にユーザーの質問に対する答えが含まれていなければ、いくら検索しても有用なコンテキストは得られません。LLMは与えられた情報が不十分な場合、辻褄を合わせるために存在しない情報を幻覚として生成してしまうことがあります (Seven RAG Pitfalls and How to Solve Them | Label Studio)。その結果、「それらしいが実は誤った回答」や「質問に対する的外れな回答」になる恐れがあります。(対策: データ整備の項を参照)
- 検索の不備(重要文書が検索でヒットしない): 答えはデータ内にあるのに検索部分がそれを見つけられないケースも精度低下の大きな原因です。たとえば、適切な埋め込みができておらず類義語に対応できなかったり、ランク付けアルゴリズムのチューニング不足で本来上位に来るべき関連文書が下位に埋もれてしまうことがあります (Seven RAG Pitfalls and How to Solve Them | Label Studio)。このようにRetrieverが正解にたどり着けないと、LLMには無関係または間接的な文脈しか与えられないため、正確な回答は困難になります。特にドメイン固有の専門用語が質問とデータで食い違っている場合(例:「退職金」と「確定拠出年金」のように表現が異なるが意味関連するケース)、検索のミスマッチが起きやすいです。(対策: 検索精度向上の項を参照)
- コンテキストの不適切または不足: 検索自体はうまくいっていても、その結果の利用方法に問題がある場合があります。典型的なのはコンテキストウィンドウの制限による情報欠落です。LLMには一度に与えられるトークン数(入力長)の上限があるため、検索で見つかった文書が長すぎると重要部分が切り落とされてしまうことがあります (Seven RAG Pitfalls and How to Solve Them | Label Studio)。あるいは文書の分割(チャンク化)が粗すぎて、一つのチャンクに関係ない内容が混在していると、LLMに渡した際にノイズとなり肝心の内容を埋もれさせてしまいます。また、複数の関連文書を結合するコンソリデーション処理が適切でないと、回答に必要な情報がプロンプト内に含まれないケースもあります。(対策: 文書分割とプロンプト設計の項を参照)
- 生成モデル側の問題(情報抽出ミス・フォーマット不備など): コンテキスト内に答えがあっても、LLMがそれを正しく読み取れない場合があります。これはコンテキスト内の情報量が多くノイズが含まれる時や、複数文書で微妙に矛盾する記述がある場合に起こりがちです (Seven RAG Pitfalls and How to Solve Them | Label Studio)。結果として質問に対する回答を部分的にしか拾えなかったり、一貫性のない説明になったりします。また、生成された回答がユーザーの期待する形式と異なる(箇条書きが欲しいのに長文になっている、など)場合も、不満の原因となります (Seven RAG Pitfalls and How to Solve Them | Label Studio)。これらは厳密には精度(正確さ)というより回答品質の問題ですが、実運用では「使えない回答=精度が低い」と認識されるため無視できません。(対策: プロンプト工夫・出力制御の項を参照)
- その他の落とし穴: 例えば最新情報への未対応もRAG導入時に陥りがちな問題です。知識ベースを定期更新しないと、古い情報を元に回答してしまい誤答となるリスクがあります (RAG: Why Does It Matter, What Is It, and Does It Guarantee Accuracy?)。また、ユーザーからの質問が漠然としすぎている場合(例:「最近の技術動向について教えて」)、検索キーワードが定まらず適切な文書を引けないこともあります。その結果、関連性の低い文脈ばかり集まってしまい、LLMが見当違いの説明をしてしまうことがあります (Why your RAG is not working?. Pitfalls of simple retrieval, solutions… | by Saurabh Singh | Medium)。
以上のように、RAGシステムにはデータ、検索、生成の各段階で様々な失敗要因が存在します。それぞれに対策を講じることで精度改善が可能ですが、まずは自社システムにおいてどの段階がボトルネックになっているかを検証することが重要です。
改善アプローチ:企業事例(東京ガス)に学ぶ
上記のような課題に対し、実際の企業導入では試行錯誤を経て改善アプローチが取られています。ここでは東京ガス株式会社の事例を参考に、RAG導入・運用のポイントを紹介します。
東京ガスでは社内向け生成AIチャットボット「AIGNIS-chat」にRAG技術を導入し、専門性の高い社内問い合わせに対して社内データを参照した的確な回答を生成する取り組みを行いました (生成AIを搭載した社内アプリを独自開発・利用開始 ~RAG技術搭載のチャットツールやOne to Oneマーケティング自動実行ツールを本格導入~ | 東京ガス株式会社のプレスリリース)。従来、社内からの問い合わせ対応では担当者が分厚いマニュアルやQ&A集をめくりながら回答するため時間がかかっていましたが、RAG活用によって必要な情報を即座に検索し回答に反映できるようになりつつあります (生成AI・RAGの導入で業務の効率化を進める コーディングや翻訳業務の作業時間を3割減 東京ガス株式会社 | PROMPTY)。その結果、問い合わせ対応に費やす時間を大幅に削減し、業務効率化につなげています。
しかし、導入当初から高精度な回答が得られたわけではなく、東京ガスでは短期間に多数のPoC(概念実証)を実施してユースケースごとの効果を検証しながら段階的に精度向上を図ったといいます (東京ガスの「第3の創業」と生成AIの融合Deloitte との協働による変革の挑戦|経営者のための生成AI)。具体的には、NTTデータと共同開発で技術基盤を整備し(RAGによる検索や使いやすいUI機能の開発支援など) (東京ガスの「第3の創業」と生成AIの融合Deloitte との協働による変革の挑戦|経営者のための生成AI)、その後は現場ユーザーへの周知教育や使い方のサポートに力を注いだとのことです (東京ガスの「第3の創業」と生成AIの融合Deloitte との協働による変革の挑戦|経営者のための生成AI)。このように、単にシステムを構築するだけでなく 「人間側のリテラシー向上」 も重視して展開していくことが、現場でRAGを使いこなす上で重要だと述べられています (生成AI・RAGの導入で業務の効率化を進める コーディングや翻訳業務の作業時間を3割減 東京ガス株式会社 | PROMPTY)。
東京ガスの事例から得られる教訓として、以下のポイントが挙げられます:
- 社内データの積極活用: 従業員が必要とする社内ナレッジ(マニュアル、提案書、契約書など)を幅広くデータベース化しRAGで引けるようにしたことが、回答精度向上に寄与しました。専門用語や社内略語にも対応可能な検索ができるようになり、従来の汎用チャットボットでは難しかった高度な質問にも答えられるようになっています (生成AIを搭載した社内アプリを独自開発・利用開始 ~RAG技術搭載のチャットツールやOne to Oneマーケティング自動実行ツールを本格導入~ | 東京ガス株式会社のプレスリリース)。
- 段階的なPoCと改善: 最初から完璧を目指すのではなく、小さなユースケースごとにPoCで効果検証→本格導入という流れを繰り返し、うまくいかない点はその都度チューニングやデータ追加を実施しました。特に検索で欲しい情報が出ない場合はデータソースを追加したり、プロンプトを調整するといった改善を迅速に行っています。
- 専門パートナーとの協業: 内製が難しい部分(生成AIの基盤構築やUI/UX改善など)では専門ベンダーと協力し、最新技術を取り入れながら実装しています (東京ガスの「第3の創業」と生成AIの融合Deloitte との協働による変革の挑戦|経営者のための生成AI)。これにより短期間でのアプリ開発が可能になり、現場からのフィードバックを素早く反映するサイクルを実現しています (東京ガスの「第3の創業」と生成AIの融合Deloitte との協働による変革の挑戦|経営者のための生成AI)。
- ユーザー教育と展開促進: システム導入後、利用者が効果的に使いこなせるよう社内ポータルでユースケース紹介やプロンプト例を共有するなど、従業員のリテラシー向上にも注力しています (生成AI・RAGの導入で業務の効率化を進める コーディングや翻訳業務の作業時間を3割減 東京ガス株式会社 | PROMPTY)。これにより「使えば業務が楽になる」という実感を広め、現在ではグループ内で3,500名以上が生成AIチャットボットを日常的に活用するまでに至っています (生成AIを搭載した社内アプリを独自開発・利用開始 ~RAG技術搭載のチャットツールやOne to Oneマーケティング自動実行ツールを本格導入~ | 東京ガス株式会社のプレスリリース)。
このように、RAG導入の現場では 技術面(データ・アルゴリズム) と 運用面(人の活用促進) の双方で工夫を重ねることが成功のカギとなります。東京ガスの例は、落とし穴に直面した際にデータ拡充やチューニングで精度向上を図りつつ、従業員にも寄り添った展開をする好例と言えるでしょう。
ファインチューニングとの違いとRAGの利点
生成AIを自社データに適用する方法としては、RAGの他にファインチューニング(追加学習)があります。ファインチューニングは、既存のLLMに自社固有のデータで追加訓練を行い、モデル自体に知識を埋め込む手法です。一方でRAGは前述したようにモデル本体はそのままに、外部データを検索で補うことで知識を提供します (RAG vs. Fine-tuning | IBM)。両者のアプローチの違いと利点を整理します。
- 知識の取り込み方: RAGはモデルを直接書き換えず、外部データベースへのアクセスを通じて知識を取り込みます (RAG vs. Fine-tuning | IBM)。モデルはプロンプトとして提供されたデータを見るだけなので、基盤となるLLMは汎用モデルのままです。一方、ファインチューニングでは追加データを用いてモデルの重みを調整し、モデル内部に知識やタスク適応を組み込みます (RAG vs. Fine-tuning | IBM)。このため、ファインチューニング後のモデルは特定領域に特化した振る舞いを示すようになります (RAG vs. Fine-tuning | IBM)。
- 最新性と保守: RAGの大きな利点は最新情報への対応と保守の容易さです。RAGでは知識源となるデータベースを更新すればモデルは即座に新情報を扱えます。たとえば社内規程が改定された場合でも、文書データを差し替えれば次の問い合わせから新ルールに基づく回答が可能です (RAG vs. fine-tuning)。LLM自体の再学習は不要なので、継続的なアップデートがしやすい点はメリットです。一方でファインチューニングでは、新情報を反映するたびに追加学習を行う必要があり、コストも時間もかかります (What is RAG? – Retrieval-Augmented Generation AI Explained – AWS)。大型モデルの再学習は計算資源を大量に要するため頻繁には実施できず、その間にモデルの知識が陳腐化してしまう(リリース時点で既に古くなる)問題があります (RAG vs. Fine-tuning | IBM)。このように、動的な知識更新に関してはRAGに軍配が上がります。
- コストとスケーラビリティ: 上述の通り、ファインチューニングはモデル規模によっては非常に高コストです (What is RAG? – Retrieval-Augmented Generation AI Explained – AWS)。一方RAGは既存の大規模モデルをそのまま利用し、外部の検索基盤を用意する形なので、初期構築こそ必要なものの追加学習ほどの計算リソースは不要です。企業内で複数のチャットボットを立ち上げる場合でも、共通の検索基盤とLLM APIを使い回すことでスケールさせやすいという利点があります。また、RAGは回答と共に出典(ソース)を提示することも比較的容易で、ユーザーが回答の根拠を辿れるようにできるため信頼性向上にもつながります (RAG vs. fine-tuning)。ファインチューニングモデルでは出典がモデル内部に埋め込まれて不明瞭になるため、回答根拠を示すには追加の工夫が必要です。
- 精度と応用範囲: ファインチューニングしたモデルは特定ドメインに最適化されるため、適切なデータと手法で行えば高い精度が期待できます (RAG vs. Fine-tuning | IBM)。特に入力クエリ自体が曖昧な場合でも、モデルがドメイン知識を総動員して推論できる点は強みです(例:専門用語の言い換えや関連知識の活用)。一方RAGは基本的に与えられたデータ内から答えを見つけるアプローチなので、データに無い質問には答えられません。しかしその制約があるからこそ、誤った推測をしにくいとも言えます。RAGでは回答に用いたデータが手元に残るため、検証や追加調査も容易です (What is RAG? – Retrieval-Augmented Generation AI Explained – AWS)。総じて、「未知の質問に対して創造的な推論をする」のがファインチューニングモデル、 「既知の情報を的確に探し出して答える」のがRAGという使い分けになります。
以上を踏まえると、多くの企業ユースケースではまずRAGで実装し、不足があればポイントでモデルをチューニングする方法がコスト・労力の面で現実的と言えます。RAGはLLMの汎用言語理解力を活かしつつ、自社データで補強することで「社内に詳しいAIアシスタント」を比較的短期間に実現できるアプローチなのです (RAG Vs Fine Tuning: How To Choose The Right Method)。
精度向上のための実践的な工夫
最後に、RAGシステムの回答精度を向上させるために現場で有効な工夫やベストプラクティスを紹介します。以下のポイントに留意することで、前述の落とし穴を回避しやすくなります。
- 知識データの整備と更新: RAGの基盤となる社内データセットは「答えの宝庫」です。まずはこの知識ベースを充実させ、網羅性と正確性を高めましょう。重要な資料が欠けていないか、人手でチェックしてギャップを補うことも有効です (Seven RAG Pitfalls and How to Solve Them | Label Studio)。また情報が古いままだと誤答の原因になるため、データは定期的に更新し最新状態を保つことが必要です (RAG: Why Does It Matter, What Is It, and Does It Guarantee Accuracy?)。不要な重複データや矛盾する記載があればクレンジング(清掃)し、一貫性のあるナレッジベースにします (Seven RAG Pitfalls and How to Solve Them | Label Studio)。データ整備なくして高品質な回答なし、というくらい重要なステップです。
- ドキュメントの前処理・構造化: 原稿のままの長大な文書をそのまま検索させるのではなく、適切なサイズに分割し、セクションごとのメタデータ(タイトルやカテゴリ、日時など)を付与して索引化すると効果的です。チャンク分割は意味単位で行い、1チャンクに複数トピックが混ざらないようにすると検索精度が向上します (Seven RAG Pitfalls and How to Solve Them | Label Studio)。またユーザーの質問カテゴリに応じて検索対象を絞り込む仕組み(例:「技術質問」なら技術文書のみ検索)を用意すると、ノイズ低減につながります。
- 検索精度向上のテクニック: Retrieverの性能を高めるために様々な手法が考案されています。まずベクトル埋め込みモデル自体をドメインに合わせてチューニング(例えば社内コーパスでファインチューニング)すると、専門用語の類義表現にも強くなります。加えて、ベクトル類似検索の結果を再ランクする仕組みも有効です (Seven RAG Pitfalls and How to Solve Them | Label Studio)。たとえば一度に上位50件取得し、その中から質問とのマッチ度合いを再評価して重要度順に並べ直す(二段階検索)ことで、より関連性の高いコンテキストを選別できます。また、クエリ拡張も強力な手法です。ユーザー質問そのものが短く曖昧な場合、LLMに「質問の意図を補完するようなキーワード」や「関連する言い換え質問」を生成させて検索に加えることで、本来ヒットしなかった文書を拾える可能性があります (Why your RAG is not working?. Pitfalls of simple retrieval, solutions… | by Saurabh Singh | Medium) (Why your RAG is not working?. Pitfalls of simple retrieval, solutions… | by Saurabh Singh | Medium)。これら検索側の工夫により、「見つからない」「関係ないものが出る」といった問題を徐々に潰していけます。
- プロンプト設計と回答誘導: LLMへのプロンプトの書き方次第で、回答の正確さ・形式は大きく変わります。システムメッセージなどで「与えられた情報から回答し、それ以外は答えない」旨を明示すると、幻覚の抑制に役立ちます。またユーザーに返すフォーマット(箇条書きやJSONなど)が決まっているなら、その指示もプロンプトに含めます (Seven RAG Pitfalls and How to Solve Them | Label Studio)。長い回答が不要なら「120文字以内で簡潔に答えて」と制約することも可能です。さらに、質問内容が漠然としている場合には生成モデル側で確認の質問をしたり、裏でクエリを言い換えて再検索するなどの対話的なアプローチも有効でしょう (Seven RAG Pitfalls and How to Solve Them | Label Studio)。プロンプトは一度作って終わりではなく、モデルの出力を見ながら改善を重ねていく作業と捉えるとよいでしょう。
- 評価とフィードバックループ: RAGシステムの精度を高めていくには、ユーザーからのフィードバックやテスト質問での評価結果を蓄積し、改善に活かすことが重要です。回答が不十分だったケースについて原因が検索側か生成側かを分析し、データ追加・検索調整・プロンプト修正といった対応策を講じます。必要であれば回答を人手で補正したり、特定の質問に対する想定回答をあらかじめ用意しておく(LLMのFew-shotプロンプトに組み込む)ことで、信頼性を高めることもできます。現場で運用しながら継続的にチューニングしていくことで、時間の経過とともに精度の底上げが図られていきます。
以上、RAGの仕組みと導入ノウハウについて解説しました。検索部分と生成部分を組み合わせるRAGは、適切に構築すれば社内業務で強力な知識活用ツールとなります。 一方で両者のバランスが崩れると期待した成果が得られないため、本記事で述べたデータフローの理解と精度向上の工夫を踏まえて、継続的に改善サイクルを回すことが大切です (Seven RAG Pitfalls and How to Solve Them | Label Studio)。RAGを上手に活用し、社内の知見を最大限に引き出せる生成AIシステムを構築していきましょう。