GitHub Copilot が「記憶」を持った ― エージェンティックメモリの登場
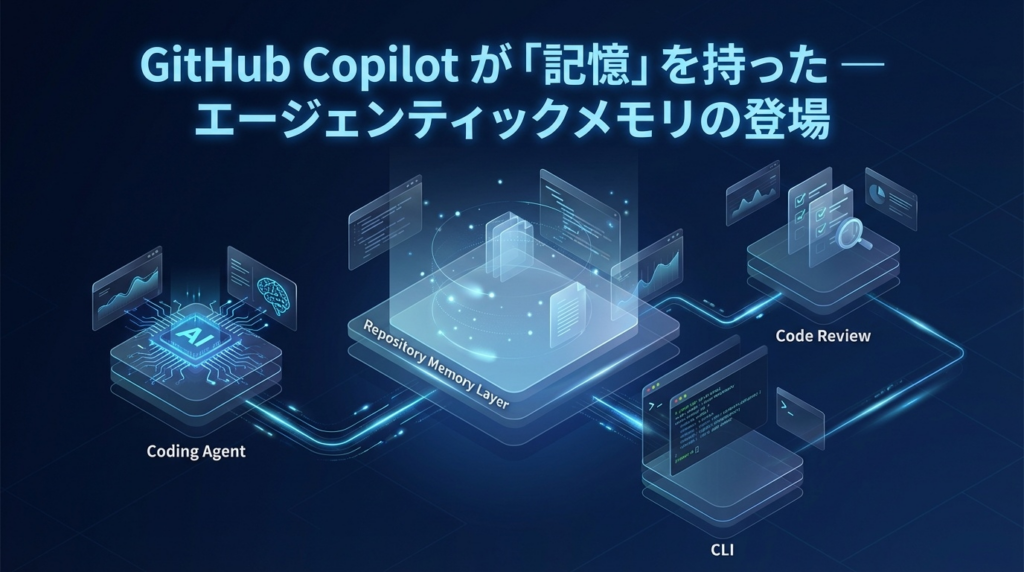
GitHub Copilot に、コードベースについて学んだことを継続的に覚えて活用する「エージェンティックメモリ(Copilot Memory)」が追加されました。
これにより、Copilot が毎回ゼロから文脈を学び直すのではなく、リポジトリ固有の知識をだんだん蓄えていく「学習する相棒」に近づいています。
エージェンティックメモリとは何か
エージェンティックメモリは、Copilot がリポジトリでの作業を通じて自動的に生成する「メモリ」の仕組みです。
- メモリはリポジトリ固有の小さな知識断片(パターンやルール、設計方針など)。
- 例: 「このリポジトリでは DB 接続はユーティリティ関数 X を経由する」「設定 A と B は常に同期させる必要がある」など。
- メモリはリポジトリ外には持ち出されず、そのリポジトリ内の Copilot 操作でのみ利用されます(プライバシーとセキュリティのため)。
現在、このメモリは以下の Copilot 機能で利用されています。
- Copilot coding agent(GitHub 上のエージェント)
- Copilot code review(PR レビュー)
- Copilot CLI
面白いのは、これらが「クロスエージェント」でメモリを共有する点です。coding agent が学んだ知識を、後から code review が利用する、といった連携が可能になっています。
ステートレスな LLM に「記憶」を足すという設計
従来の Copilot は各セッションごとにコンテキストを忘れるため、プロジェクト固有の前提を何度も説明し続ける必要がありました。
エージェンティックメモリは、この「毎回同じことを教え直す」問題を解消するためのシステムレイヤです。
設計上のポイントは次のとおりです。
- メモリは LLM 本体ではなく、外部のメモリシステムに保存される。
- メモリごとに「どのコードから導かれたか」という引用(citations)が紐づいている。
- Copilot がメモリを使うときは、毎回その参照先コードをチェックし、まだ妥当かを検証してから利用する(Just-in-Time 検証)。
この「コード側に裏付けがある知識だけを使う」「使う直前に再検証する」という設計により、LLM の幻覚的な思いつきではなく、実際のコードに裏打ちされたメモリだけが残るようになっています。
メモリのライフサイクル ― 自己修復する記憶
メモリは一度作ったら永遠に残るわけではなく、一定期間が過ぎると自動的に削除されます。
- 各メモリは 28 日で自動削除される。
- ただし、その期間中に再度検証されて使われると、同じ内容の新しいメモリが生成され、事実上「延命」される。
- コード側に変更が入ってメモリと矛盾する場合、検証時に気づいて更新・置き換えされる、という自己修復的な動きをします。
また、メモリは書き込み権限を持ち、かつ Copilot Memory が有効になっているユーザーの操作に対してのみ作られます。
メモリはリポジトリ単位で共有されるため、そのリポジトリに対して Copilot Memory を使えるメンバーは、同じメモリを一緒に活用できます。
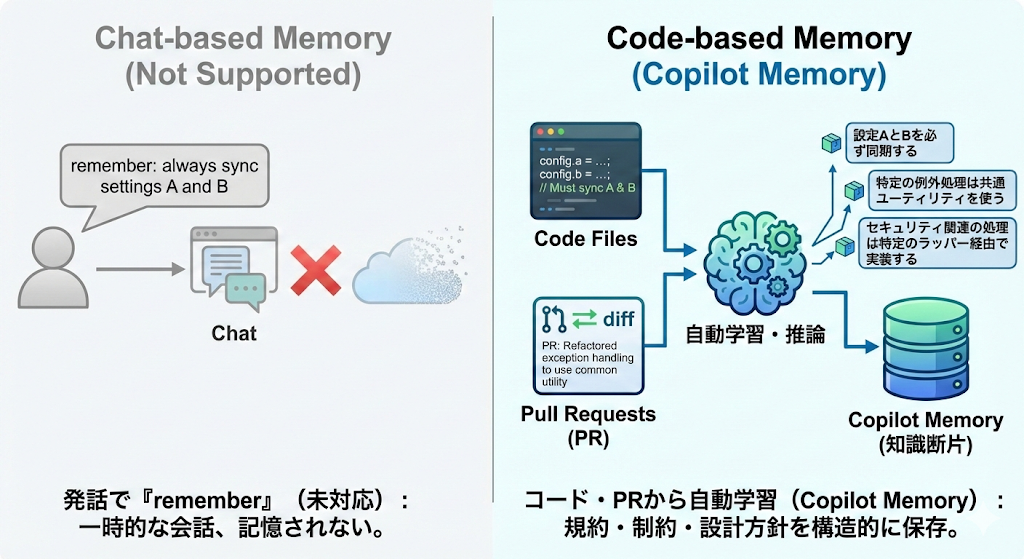
「覚えて」と言えば記憶してくれるのか?
「Copilot に『これは覚えておいて』と明示的に頼めるのか?」は、実務的にも気になるポイントだと思います。
GitHub Copilot のエージェンティックメモリについては、少なくとも公式ドキュメントには「特定のフレーズでメモリ保存を明示トリガーする」ような仕様は書かれていません。
メモリは、あくまで PR やコードの変更内容などから Copilot が自律的に「長期的に役立ちそうだ」と判断したときに生成される、という位置づけです。
一方で、Microsoft 365 Copilot 側の「Copilot メモリ」は、「覚えて」「忘れて」といったユーザーの指示で明示保存・削除する UX が導入されています。
ここは GitHub Copilot のリポジトリ向けメモリと混同しやすいので、ブログでは区別して解説しておくと親切です。
GitHub Copilot の場合は、「チャットで言ったから覚える」ではなく、「コード・PR として残したことを Copilot が抽出して覚える」と理解するのが素直だと思います。
Copilot Memory を有効化する
対象プラン
Copilot Memory は、以下の有償プランで利用できるパブリックプレビュー機能です。
- GitHub Copilot Enterprise / Business
- GitHub Copilot Pro / Pro+(個人)
個人(Pro / Pro+)での有効化手順
- GitHub 右上のプロフィールアイコンから「Copilot settings」を開く。
- 「Features」セクション内の「Copilot Memory」を探す。
- ドロップダウンで「Enabled」を選択する。
これで、そのアカウントで利用する Copilot coding agent / code review / CLI が、対象リポジトリでメモリを作成・利用できるようになります。
組織・エンタープライズでの有効化
- GitHub 右上のプロフィールから対象 Organization を選択。
- 「Settings」→ 左メニューの「Copilot」→「Policies」を開く。
- 「Features」内の「Copilot Memory」を「Enabled」に設定する。
組織で有効化すると、その組織で Copilot ライセンスを持つユーザーが、Organization 配下のリポジトリで Copilot Memory を利用できるようになります。
リポジトリごとのメモリを確認・削除する
どんなメモリが溜まっているかは、リポジトリ単位で確認できます。
- 対象リポジトリのトップページを開く。
- 「Settings」タブを開く。
- 左メニューの「Code & automation」→「Copilot」→「Memory」をクリック。
- 新しい順にメモリ一覧が表示され、不要なものはここから削除可能です。
もし Copilot が誤った推論をしていたり、機密情報を含むメモリが生成されてしまった場合は、この画面から手動で削除しておくと安心です。
現場でのユースケース例
ブログの読者に具体的なイメージを持ってもらうために、次のようなユースケースを挙げておくと伝わりやすくなります。
- 設定値の同期ルール
例: 「フロントとバックの設定ファイルで API バージョンを必ず一致させる」というパターンを Copilot がメモリ化し、以後の PR で差分があれば code review が警告してくれる。 - 接続方式やラッパーの統一
DB 接続やログ出力など、「このリポジトリでは必ずユーティリティ関数経由で行う」といったルールが、coding agent の提案や修正に自然に反映される。 - 実験的な変更のフォロー
マージされなかった PR からもメモリが生成されることがあるが、実際のコードベースに裏付けがなければ検証で弾かれるため、過去の実験が邪魔をするリスクは低く抑えられている。
まとめに代えて ― 「学習する Copilot」とどう付き合うか
エージェンティックメモリは、「リポジトリごとの長期記憶」を Copilot に持たせるための土台となる機能です。
現状は coding agent / code review / CLI に限定されていますが、今後は他の Copilot 機能や、個人・組織スコープにも広がっていく計画が示されています。
運用上は、「チャットでお願いして覚えさせる」というよりも、「PR やコードの形でルールを明文化しておき、Copilot に拾わせる」前提で設計・レビューのプロセスを整えるのが相性が良さそうです。
このあたりを踏まえつつ、自分のチームのリポジトリでどんな知識を Copilot に覚えさせたいかを考えながら試してみると、単なるオートコンプリートから「チームの文脈を共有する相棒」へと役割が変わってくるはずです。