『Codified Context: Infrastructure for AI Agents in a Complex Codebase』日本語訳
AI仕様駆動開発における論文が出ていました。大規模開発における実証実験レポートのようです。我々もいくつものプロジェクトを行なっています。とても参考になりますね。以下、日本語訳です。
—
論文タイトル
Codified Context: Infrastructure for AI Agents in a Complex Codebase
著者
Aristidis Vasilopoulos
所属
Independent Researcher, USA
論文URL
https://arxiv.org/pdf/2602.20478.pdf
arXiv
2602.20478v1 [cs.SE], 2026年2月24日
本記事は、上記論文の内容をもとに、構成を保ちながら日本語で忠実に訳したものです。出典論文はアップロードされたPDFです。
要旨
LLMベースのエージェント型コーディング支援は、永続的な記憶を欠いている。すなわち、セッションをまたぐ一貫性を失い、プロジェクトの慣習を忘れ、既知の誤りを繰り返す。近年の研究では、開発者がマニフェストファイルを通じてどのようにエージェントを設定しているかが特徴づけられているが、大規模でマルチエージェントなプロジェクトにおいて、そのような設定をどのように拡張するかという課題は依然として残っている。
本論文では、108,000行規模のC#分散システムの構築中に開発された、3要素から成るコード化コンテキスト基盤を提示する。すなわち、慣習、検索フック、オーケストレーションプロトコルを符号化したホットメモリ憲章、19体の専門領域エキスパートエージェント、オンデマンドで参照する34本の仕様文書から成るコールドメモリ知識ベースである。
283回の開発セッションにわたる基盤の成長と相互作用パターンの定量指標を報告し、さらに、コード化コンテキストがセッションをまたいで伝播し、失敗防止と一貫性維持に寄与したことを示す4つの観察事例を示す。この枠組みは、オープンソースのコンパニオンリポジトリとして公開されている。
キーワード
AI支援ソフトウェア開発、マルチエージェントシステム、コンテキスト基盤、ソフトウェアアーキテクチャ、エージェント型ソフトウェア工学、コンテキストエンジニアリング
1. はじめに
GitHub Copilot、Cursor、Claude Code などのAIコーディングエージェントは、何百万もの開発者に利用されるに至っており、近年の研究では、複雑な開発タスクを計画・実行・反復できる完全エージェント型システムも報告されている。これらのツールは幅広いプログラミング知識を備えている一方で、プロジェクト記憶を欠いている。各セッションは、過去のセッション、確立済みの慣習、過去の失敗についての認識を持たないまま始まる。
特定のプロジェクトに対して一貫した出力を得るには、セッションをまたいで持続する知識が必要である。しかし、単一ファイルのマニフェストである .cursorrules、CLAUDE.md、AGENTS.md は、中規模を超えるコードベースには拡張しにくい。1,000行のプロトタイプなら単一のプロンプトで十分に記述できても、100,000行のシステムでは不可能である。AIには、プロジェクトがどのように動作するか、どのパターンに従うべきか、どの誤りを避けるべきかを、繰り返し、確実に、そして実行可能な形式で伝えなければならない。エージェントへの構造化知識移転は、依然として未解決なインタラクション設計上の課題である。
本論文はこのギャップに対し、文書をインフラとして扱うコード化コンテキスト基盤を提案する。ここで文書とは、AIエージェントが正しい出力を生成するために依存する荷重支持的な成果物である。機械可読な仕様文書をオンデマンドで利用可能にすることで、エージェントは複雑なコードベースにおいても永続的記憶を擬似的に実現できる。
このアーキテクチャは、108,000行規模のC#分散システム、すなわち MonoGame フレームワークおよび Arch Entity Component System ライブラリを基盤とするリアルタイム・マルチプレイヤー・シミュレーションを構築する過程で、反復的に開発された。アプリケーションコードとコンテキスト基盤の双方は、唯一のコード生成ツールとして Claude Code を用い、人間によるプロンプトとエージェント・オーケストレーションの指揮の下で生成された。著者の主たる背景はソフトウェア工学ではなく化学であり、このプロジェクトは、AIエージェントを用いて本来の専門外にあるソフトウェアを構築するという、新たに現れつつある利用形態の事例となっている。
1.1 貢献
第一に、本論文は、マルチエージェントAI支援開発を支えるために、プロジェクト知識を組織化する階層アーキテクチャを提案する。このアーキテクチャは、単一ファイル・マニフェストのパターンを拡張し、プロジェクト固有知識を埋め込んだドメインエキスパート・エージェント、自動タスクルーティングのためのトリガーテーブル、常時読み込まれる慣習とオンデマンド仕様を分離するホット/コールドメモリ分離を備える。
第二に、283回の開発セッションにわたる定量評価を示す。これには、基盤成長指標、相互作用パターン、人間プロンプト数、エージェント起動数、エージェントターン数、および4つの観察事例が含まれる。
第三に、代表的なエージェント仕様、MCP検索サーバ、サンプル文書、ブートストラップ用ファクトリエージェント、およびすべての分析スクリプトを含むオープンソース・フレームワークを公開する。
2. 関連研究
2.1 エージェント型コーディング・マニフェスト
開発者は、CLAUDE.md、.cursorrules、AGENTS.md など様々な名称の設定ファイルを作成し、各セッションの開始時にAIコーディングエージェントへプロジェクト固有の指示を与えるようになってきた。近年、これらのファイルを実証的に特徴づける研究が現れている。Claude Code のプロジェクトでは 72.6% がアプリケーションアーキテクチャを指定しており、この傾向は Claude Code、Codex、GitHub Copilot にまたがる2,303個のファイルでも一般化している。401件の Cursor リポジトリから、開発者が含める指示の種類についての分類も提案されている。より広いオープンソース生態系全体では採用はまだ初期段階にあり、調査対象466リポジトリのうち何らかのコンテキストファイル形式を採用していたのは約5%にとどまるが、マニフェストを使用しているプロジェクトでは、その有効性を示す定量的証拠が出始めている。AGENTS.md の存在は、中央値ランタイムを29%削減し、出力トークン消費を17%削減することと関連していた。
これらの研究は、開発者がマニフェストファイルに何を書くかを特徴づけている。本研究が扱うのは別の問いである。すなわち、プロジェクト知識が単一ファイルの範囲を超えたときに何が起こるのか、である。ここで述べるプロジェクトは、先行研究で分析されたものと同様のマニフェストから始まったが、その後、およそ26,000行に達する階層アーキテクチャへ進化した。これは先行研究で特徴づけられた典型的マニフェストの1桁以上上の規模である。最近公開された Gemini CLI 向け Google Conductor も、永続Markdownと構造化された仕様・計画・実装ワークフローにより、類似の課題に取り組んでいる。本研究は独立かつ同時並行に開発されたものであり、特定プラットフォームに結びつけるのではなく、エージェント型コーディングツールをまたいで移植可能な階層的知識組織化に焦点を当てている。
2.2 コンテキストエンジニアリング、マルチエージェント・フレームワーク、LLM支援ソフトウェア工学
マルチファイルコード生成におけるコンテキストエンジニアリングのための統合マルチツール・ワークフローは、単一エージェントシステムより高い成功率を示している。LLMにコード化された人間専門家のドメイン知識を付与することも、出力品質を改善する。本研究のアプローチは、コード化されたドメイン知識がエージェント出力を改善するという原理と整合するが、プロジェクト規模で運用される点が異なる。ここでの知識ベースは、一般的なドメイン専門知識ではなく、通常はプロジェクト固有の慣習、アーキテクチャ上の意思決定、既知の失敗モードを記述する。
コンテキストエンジニアリングは、1,400本以上の論文から抽出した基礎要素の分類体系を備える分野として定式化されている。Agentic Context Engineering は、コンテキストを、生成・省察・キュレーションのサイクルによって洗練される「進化するプレイブック」と見なす。この研究は、反復最適化により短く一般的なプロンプトへ収束しがちな「簡潔性バイアス」も指摘しており、これは、本研究で観察された「専門エージェントが信頼できる性能を発揮するには、相当量の埋め込みドメイン知識が必要である」という知見と整合する。
AutoGen、ChatDev、MetaGPT などのマルチエージェント協調フレームワークは、エージェント間通信、タスク分割段階、標準手順のワークフロー埋め込みを扱う。これに対し本研究の貢献は補完的であり、それらが「エージェントがどのように協調するか」を定義するのに対し、本研究は「エージェントが依存する知識をどのように構造化するか」に焦点を当てる。関連するが異なるアプローチとして、コードベース自体に対する埋め込みベース検索がある。Cursor のコードベースインデキシングのようなツールがこれを実装している。これらのシステムが索引化するのはコードであるのに対し、コード化コンテキスト基盤が索引化するのはコードに関する知識、すなわち、どの単一ソースファイルにも存在しない設計意図、制約、失敗モードである。
3. アーキテクチャ
本論文では、コード化コンテキスト基盤を、明示的に機械消費のために書かれた構造化成果物、すなわち、主たる読者が開発者ではなくAIエージェントである文書群と定義する。このアーキテクチャは、読み込み戦略と更新頻度がそれぞれ異なる3つの階層から成る。ホットメモリ、ドメイン専門家、コールドメモリである。
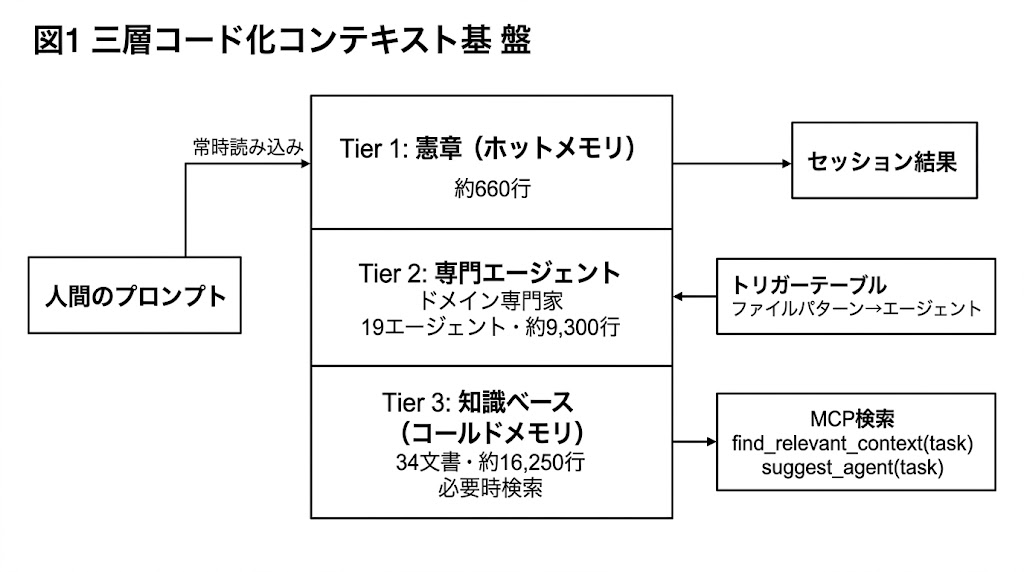
3.1 Tier 1: プロジェクト憲章(ホットメモリ)
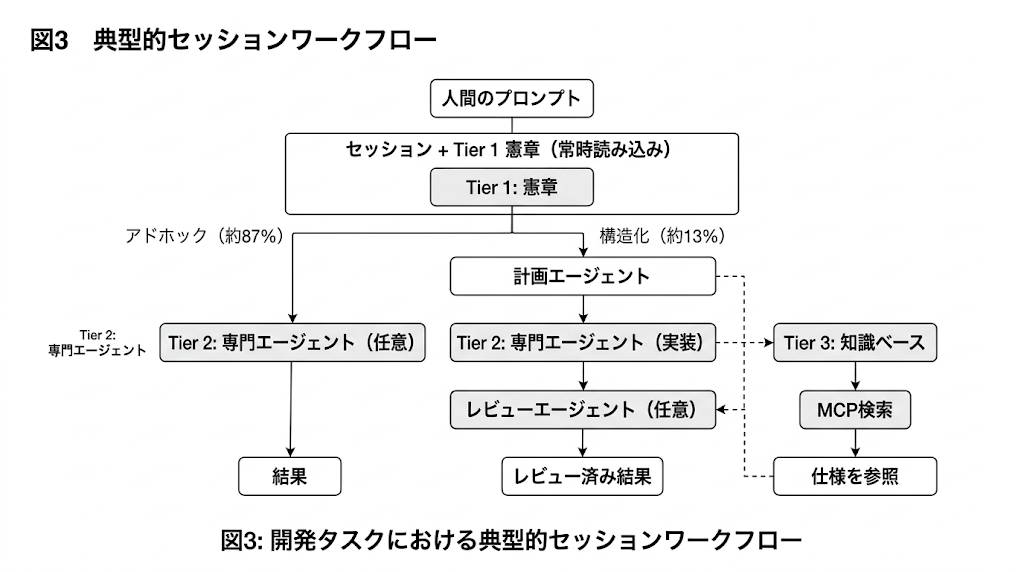
憲章は、各AIセッションに自動的に読み込まれる単一のMarkdownファイルである。そこでは、コード品質基準、命名規約、ビルドコマンド、Tier 3 の詳細仕様への参照を伴うアーキテクチャパターン要約、一般的操作のチェックリスト、既知の失敗モード、そしてタスクを専門エージェントへ振り分けるオーケストレーション・プロトコルが定義される。
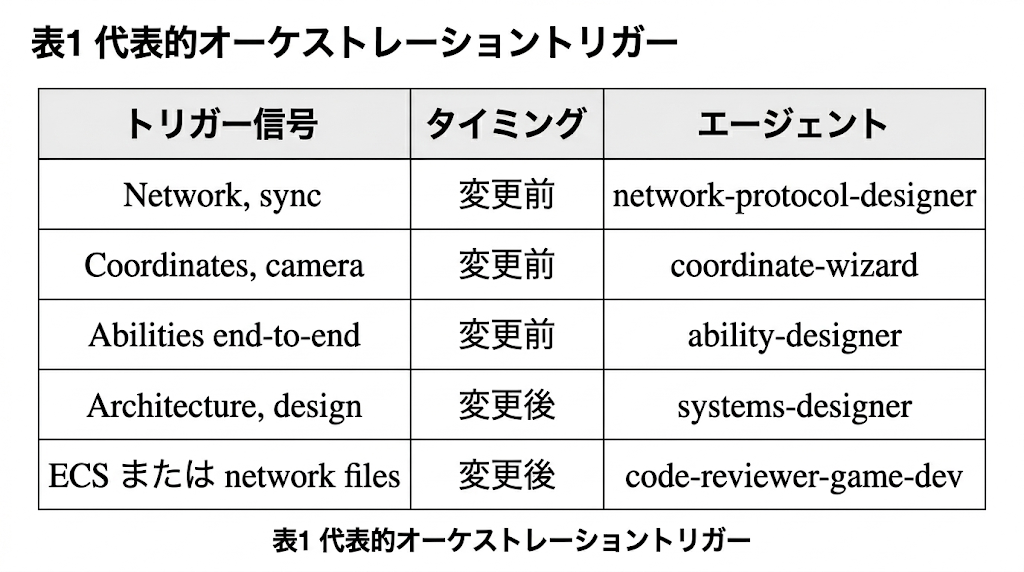
3.1.1 オーケストレーション・プロトコル
憲章には、主としてどのファイルが修正されるかという観測可能なシグナルに基づいて、タスクを適切な専門エージェントへルーティングするトリガーテーブルが埋め込まれている。たとえば、ネットワークや同期の変更前には network-protocol-designer、座標やカメラの変更前には coordinate-wizard、能力のエンドツーエンド変更前には ability-designer、アーキテクチャや設計変更後には systems-designer、ECSまたはネットワークファイルの変更後には code-reviewer-game-dev を呼び出す。
3.2 Tier 2: 専門化エージェント
19本のエージェント仕様ファイルが、コードベースの特定領域に対するドメインエキスパート人格を定義している。これらのエージェントは2つの能力クラスに分かれる。ネットワーキング、アーキテクチャ、デバッグのような複雑領域を扱う高能力エージェント8体と、より焦点の絞られたタスク向けの標準能力エージェント11体である。各仕様は、担当ドメイン範囲、利用可能なツールと権限、関連する Tier 3 文書、期待される出力形式、一般的なドメイン誤りを宣言する。一部エージェントは安全性のため読み取り専用である。
エージェントはドメイン事前プライミング機構として機能する。豊富で構造化されたコンテキストは、より信頼できるエージェント行動を生む。たとえば、ダメージ同期コードをレビューするネットワーキングエージェントは、クライアント予測の欠如や不正な権限チェックなど、汎用セッションでは見逃しやすい問題を検出する。これは、その仕様がドメイン固有の失敗モードでエージェントを事前にプライムしているためである。

3.3 Tier 3: コード化コンテキストベース(コールドメモリ)
知識ベースは34本のMarkdownファイルからなり、各文書が1つのサブシステムを記述する。仕様文書作成を支配する設計判断は3つある。第一に、文書はAI消費のために書かれる。つまり、ファイルパス、パラメータ名、期待動作を含む明示的なコードパターンを記述する。第二に、仕様は開発者の指示のもとAIによって生成・更新される生きた文書である。第三に、各文書は単一サブシステムにスコープを限定し、標的検索を可能にする。
3.3.1 知識検索サービス
知識ベースは、Model Context Protocol(MCP)サーバを通じて提供され、5つの検索ツールを備える。
list_subsystems()
get_files_for_subsystem(key)
find_relevant_context(task)
search_context_documents(query)
suggest_agent(task)
現行実装はキーワード部分文字列一致を用いており、意味検索については今後の課題として論じられている。
4. 評価
4.1 方法論と範囲
本論文はシステム論文かつ経験報告であり、主たる貢献は統計的有効性の証明ではなくアーキテクチャそのものにある。アーキテクチャ記述は、プロジェクトのGit履歴から得た基盤規模と成長の定量指標、会話履歴から抽出した相互作用指標、4つの観察事例、保守コストと失敗モードに関する質的観察によって補完される。
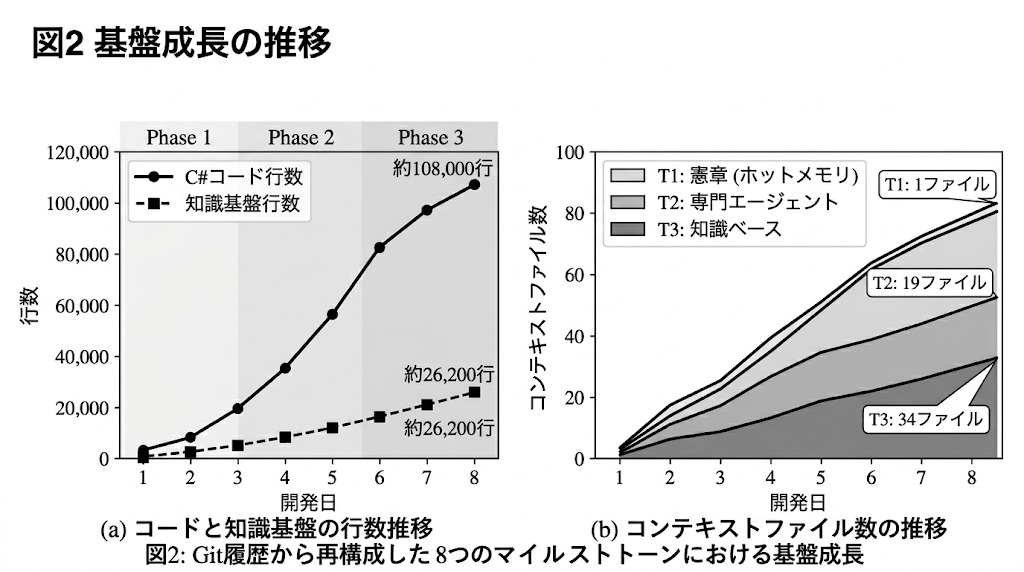
4.2 規模と成長
このアーキテクチャは、70日間のパートタイム開発、283セッションにわたって構築されたリアルタイム分散システムの文脈で開発された。
プロジェクトの主要指標は以下の通りである。
開発期間:70日(パートタイム)
総コミット数:148
C#ソースファイル数:405
C#コード行数:108,256
ECSシステム数:45以上
ECSコンポーネント数:55以上
ネットワークメッセージ型数:35以上
人間プロンプト数:2,801
エージェント起動数:1,197
エージェントターン数:16,522
開発セッション数:283
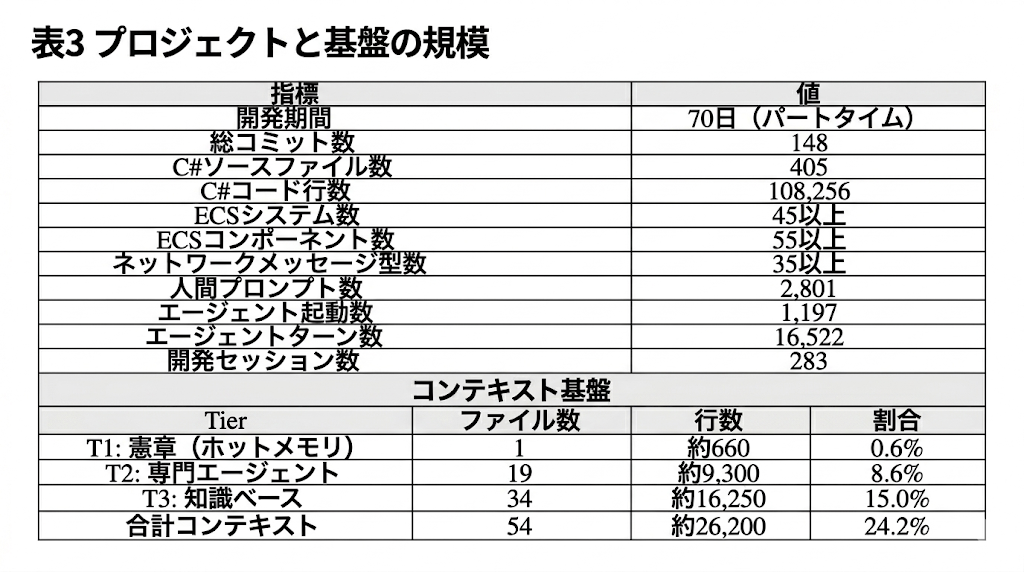
コンテキスト基盤の規模は以下の通りである。
Tier 1: 憲章 1ファイル / 約660行 / コード比0.6%
Tier 2: 専門エージェント 19ファイル / 約9,300行 / 8.6%
Tier 3: 知識ベース 34ファイル / 約16,250行 / 15.0%
合計コンテキスト 54ファイル / 約26,200行 / 24.2%
4.3 相互作用指標
相互作用データセットは、2,801件の人間プロンプト、1,197件のエージェント起動、16,522件の自律エージェントターンから成る。総相互作用数は19,323であり、1セッションあたり約9.9件の人間プロンプトとなる。オーケストレーション・プロトコルは2つのモードを支えた。plan-execute-review ワークフローに従う構造化セッションが約13%、直接実装またはデバッグを行うアドホック・セッションが約87%である。各人間プロンプトは、エージェント間連鎖を通じて約6件の自律エージェントターンを生んだ。
4.4 事例研究
4.4.1 事例1: セーブシステム — 協調文書としてのコード化コンテキスト
このプロジェクトのセーブシステムは、永続的プレイヤーデータのためのディスク層と、レベル遷移中の一時状態のためのメモリ層から成る二層アーキテクチャを採る。save-system.md 仕様は、この二層アーキテクチャ、自動保存のトリガーポイント、ゴールドのチェックポイント/ロールバック機構、ゲーム状態間のデータフローを記述する。
これはプロジェクトで最も参照された仕様であり、74セッション、12件のエージェント会話に現れた。永続化に関わるその後の複数機能は、この仕様へアクセス可能なエージェントによって実装され、二層パターンは一貫して正しく適用された。4週間にわたる74の独立セッションを通じて、セーブ関連のバグは発生しなかった。
4.4.2 事例2: UI同期ルーティング — 捕捉された経験としてのコード化コンテキスト
ショップ同期システムは、ネットワークUI仕様が存在する前に実装されたため、高頻度ゲーム状態には妥当だがUI状態機械には不適切な「非信頼配送」を一律に適用していた。その結果、ショップ開閉イベントがパケットロス時に黙って失われ、クライアント側に幽霊のようなオーバーレイが残った。
ショップ実装が安定した後、その教訓は ui-sync-patterns.md に取り込まれた。そこでは、3つのルーティング・トポロジー、配送モードの決定木、二重配送パターンが文書化された。この仕様はその後およそ10セッション、25件以上のエージェント会話で参照された。次のネットワーク化UI機能では、この仕様の決定木に直接従い、最初の実装試行で正しく二重配送パターンが適用された。
4.4.3 事例3: ドロップシステム — 知識ギャップの検出
装備システムを単一アイテム型から複数の合成可能型へリファクタリングする際、検索サービスでドロップシステム文書を探索したところ、結果はゼロ件だった。すなわち、仕様が存在しなかった。この「結果なし」自体が有益な情報であった。サブシステム全体が一度も文書化されないまま構築されており、安全にリファクタリングを進めるには、先に仕様を作成する必要があると判明したのである。
4.4.4 事例4: 決定論的RNG — 協調デバッグにおけるエージェントのドメイン知識
このプロジェクトは、同一のゲームイベントに対してホストとクライアントが同一結果を計算するよう、決定論的乱数生成器 CombatRng を用いる。時間同期リファクタリングは、この決定論性の破綻を引き起こした。デバッグセッションは、5回のコンテキストウィンドウ枯渇と84回のコード編集に及んだ。
network-protocol-designer エージェントの仕様には、正しさの柱、ハッシュ関数制約、既知の数値エッジケースといったプロジェクトの決定論理論が埋め込まれている。この埋め込み知識に基づき、エージェントは、それまでの5回の試行をすり抜けていた3つの問題を同定した。正常条件下で静かに失敗するガード節、異なるレートで更新される2つの内部クロック、そして時計補正式の符号誤りである。さらにエージェントは、戦闘RNGハッシュの入力に時刻を使うこと自体が本質的に逆効果だと結論した。時間バケット・パラメータを同期済みショットカウンタへ置き換えたことで、このバグは解消された。
5. 議論
開発期間を通じて、AI自動化は実装、描画、配線といった退屈な作業を一貫して取り除いたが、判断、すなわち設計判断、美的評価、アーキテクチャは代替しなかった。単一ファイル・マニフェストは初期段階ではこの分業を支えるが、プロジェクトが複雑化すると、エージェントは一貫性を失い、開発者は本来エージェントが処理すべき日常的実装エラーの解消へ再び引き戻される。コンテキスト基盤は、この分業をスケールさせて維持する。永続的で機械可読な仕様により、コードベースが成長しても、エージェントは正しく慣習準拠のコードを出し続ける。その結果、開発者は設計と判断に集中し続けることができる。
5.1 実務者への指針
論文では、次の6つのガイドラインが示される。
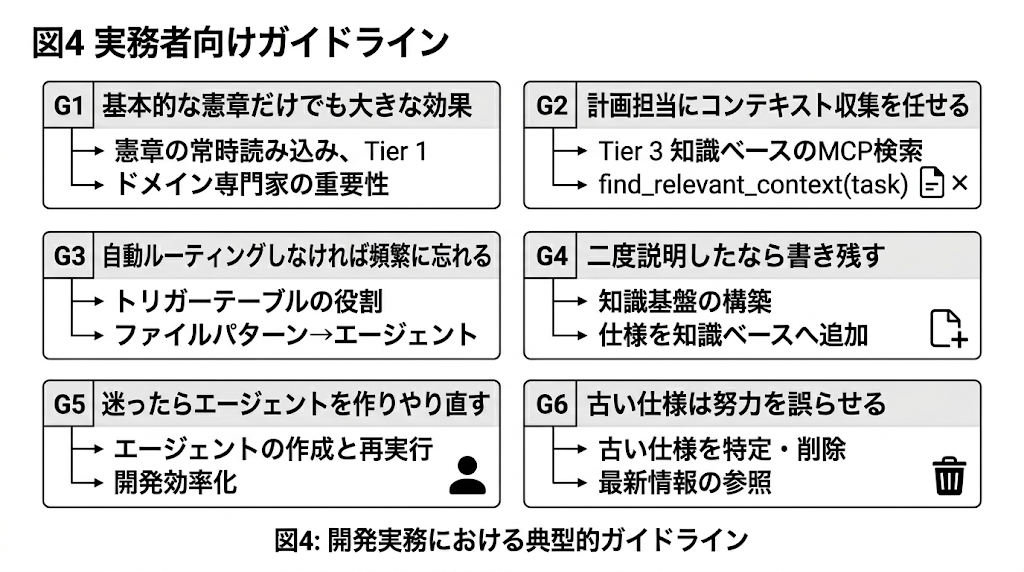
G1 基本的な憲章だけでも大きな効果がある。
G2 計画担当にコンテキスト収集を任せる。
G3 自動ルーティングしなければ、頻繁に忘れる。
G4 二度説明したなら、書き残す。
G5 迷ったらエージェントを作り、やり直す。
G6 古い仕様は努力を誤らせる。
5.2 保守コスト
実際には、仕様更新はコード変更と同じセッションで実施され、通常は関連文書の更新をAIに指示する1〜2個のプロンプトで済んだ。仕様に影響がある場合、セッションあたりおよそ5分の追加コストとなった。このセッション単位のオーバーヘッドに加え、すべてのコンテキスト文書に対する隔週レビューが行われ、各回に約30〜45分を要した。保守オーバーヘッドの平均は、週あたりおよそ1〜2時間であった。
5.3 妥当性への脅威と今後の課題
このアーキテクチャは単一開発者・単一プロジェクトで開発されたものであり、チーム環境、他のプロジェクト種別、より大規模な状況での有効性は評価されていない。評価は統制実験ではなく観察事例に依存している。そのため、このアーキテクチャが開発速度やコード品質をどの程度改善したかを統計的厳密さで定量化することはできない。実装はMCPをサポートする Claude Code を用いており、移植可能性も未評価である。今後は、各アーキテクチャ階層の有無によるタスク完了率と誤り率を測る統制ベンチマーク、意味的差分解析によるドリフト検出、埋め込みベース検索への移行、複数プロジェクトおよびチーム規模での評価が求められる。
6. 結論
本研究の中核的洞察は、プロジェクト固有知識への構造化アクセスが、AI生成コードの一貫性を大きく改善しうること、そしてその知識を、読み込み戦略と更新頻度の異なる明確な階層へ組織化できることである。本論文で提示した階層アーキテクチャ、すなわちホットメモリ憲章、専門領域エキスパートエージェント、コールドメモリ知識ベースは、プロジェクト文書を単なる成果物ではなくインフラとして扱う。すなわち、AIエージェントが正しく慣習準拠のコードを生成するために依存する、生きた仕様である。
事例研究は、コード化コンテキストが開発成果を改善する4つの異なるメカニズムを示している。仕様がセッション間協調文書として機能したこと、捕捉された経験が試行錯誤の反復を防いだこと、文書化が一度限りの努力を持続的な開発速度へ変換したこと、そして埋め込みドメイン知識が微妙で横断的なバグの協調デバッグを可能にしたことである。
コンテキスト基盤そのものも、人間のアーキテクチャ設計指揮の下でAIにより生成できる。人間の役割は、知識構造を設計し、何を記録すべきかを決めることにある。AIコーディングエージェントがより高性能になるにつれ、このアーキテクチャは、とりわけ本来の専門外にあるソフトウェアを構築するドメイン専門家にとって重要になる。コード化コンテキストが、工学経験の不足を補うからである。
コンパニオンリポジトリ
本論文のコンパニオン・フレームワークリポジトリは以下で公開されている。
ここには、代表的エージェント仕様、MCP検索サーバ、サンプル憲章および知識ベース文書、新規プロジェクトでアーキテクチャを立ち上げるための3体のファクトリエージェント、本論文で参照されたすべてのプロンプト分類スクリプトが含まれる。